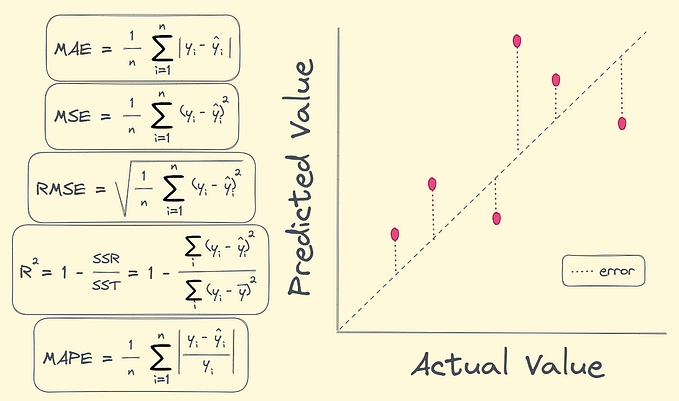
Regularization is an essential concept in machine learning, especially for models that tend to overfit by learning noise from the data. Let’s dive deep into each type of regularization, its mathematical and geometric intuition, and its practical applications with real-world data. I’ll also include some potential tricky questions to help you anticipate common challenges.
What is Regularization?
Regularization is a technique to reduce model complexity by imposing a penalty on larger coefficients. This helps prevent overfitting by encouraging the model to select only the most relevant features. Regularization is particularly useful in scenarios with high-dimensional data or when there’s multicollinearity between features.
Key Concept:
- In a high-complexity model (e.g., multiple polynomial features), regularization controls the magnitude of feature weights, simplifying the model and making it more generalizable to new data.
Types of Regularization
A. Lasso Regression (L1 Regularization)
Concept:
Lasso (Least Absolute Shrinkage and Selection Operator) is an L1 regularization method that penalizes the absolute value of the coefficients. It shrinks some coefficients to zero, effectively performing feature selection by excluding irrelevant features.
Mathematical Intuition:
For a given loss function LLL, the Lasso regularized objective function is:

where λ controls the strength of the L1 penalty. Higher λvalues lead to more regularization, setting more coefficients to zero and effectively performing feature selection.
Geometric Intuition:
The L1 constraint creates a diamond-shaped boundary in weight space, which encourages some coefficients to be zero. The optimization “bumps” into these edges, naturally pushing some coefficients to zero.
Advantages:
- Feature selection (important features are automatically selected).
- Prevents overfitting effectively, especially in high-dimensional data.
Disadvantages:
- In cases where features are highly correlated, Lasso may pick only one feature from a group, ignoring the rest.
Applications:
- Genomics and medical research: Selecting relevant genes in predictive models.
- Finance: Feature selection for pricing models, selecting essential indicators while ignoring insignificant ones.
Question:
What happens to correlated features when using Lasso?
Answer: Lasso may choose only one of the correlated features, setting others to zero. This can be a disadvantage if we want to retain all information from correlated features.
B. Ridge Regression (L2 Regularization)
Concept:
Ridge (L2 regularization) adds a penalty equal to the sum of the squared coefficients. Unlike Lasso, it does not force coefficients to zero but shrinks them towards zero, allowing all features to contribute to some degree.
Mathematical Intuition:
For Ridge, the objective function is:

Here, λ controls the L2 penalty. Increasing λ shrinks coefficients towards zero but does not set them exactly to zero, allowing all features to have some influence.
Geometric Intuition:
The L2 constraint creates a circular boundary in weight space, which encourages coefficients to be small but not exactly zero.
Advantages:
- Useful in situations with multicollinearity since it distributes weight among correlated features.
- Stabilizes predictions, reducing the model variance without removing features entirely.
Disadvantages:
- Does not perform feature selection; all features will have non-zero weights.
Applications:
- Stock market predictions: Models with many economic indicators.
- Text classification: Handling high-dimensional text features without reducing vocabulary size.
Question:
Why doesn’t Ridge regression perform feature selection?
Answer: Ridge minimizes the coefficients but does not set them to zero, allowing all features to contribute to the final prediction. This can be useful for multicollinear features.
C. Elastic Net (Combination of L1 and L2 Regularization)
Concept:
Elastic Net combines Lasso and Ridge penalties to overcome their individual limitations. It penalizes both the absolute values and the squared values of the coefficients, thus offering the advantages of both feature selection (L1) and distributed weights among correlated features (L2).
Mathematical Intuition:
The Elastic Net objective function is:

where λ1 and λ2 control the L1 and L2 penalties, respectively. By tuning λ1 and λ2, Elastic Net finds a balance between feature selection and coefficient shrinking.
Geometric Intuition:
The constraint region in Elastic Net is a blend of diamond and circular shapes, leading to both zero and non-zero coefficients, thus achieving a balance between Ridge and Lasso properties.
Advantages:
- Balances the strengths of Ridge and Lasso, especially useful for datasets with highly correlated features and those that benefit from some feature selection.
Disadvantages:
- Adds complexity in hyperparameter tuning due to the need for adjusting both λ1 and λ2.
Applications:
- Predictive analytics in health care: Balancing the need for interpretability and retaining correlated variables.
- Credit scoring models: Managing a large set of possibly correlated financial indicators.
Question:
When should we prefer Elastic Net over Lasso or Ridge?
Answer: Elastic Net is preferred when the dataset has high-dimensional and correlated features, as it combines feature selection and weight distribution.
Difference between Lasso, Ridge, and Elastic Net
Penalty Type and Effect on Coefficients
- Lasso (L1 Regularization) penalizes the absolute values of the model coefficients, leading to some coefficients being reduced to exactly zero. This results in feature selection, as it effectively removes less important features from the model.
- Ridge (L2 Regularization), on the other hand, penalizes the square of the coefficients, which encourages smaller coefficients but rarely pushes them all the way to zero. This makes Ridge useful for situations where we want to retain all features but reduce their influence.
- Elastic Net combines both the Lasso and Ridge penalties, so it penalizes both the absolute and squared values of coefficients. This approach enables Elastic Net to perform feature selection like Lasso but also handles multicollinearity (correlated features) effectively, as Ridge does.
Feature Selection
- Lasso is known for its feature selection ability, as it can set irrelevant feature coefficients to zero, effectively selecting only the most important features.
- Ridge does not perform feature selection because it shrinks coefficients towards zero without making them exactly zero, which means all features remain in the model.
- Elastic Net provides a balance by partially selecting features (like Lasso) and shrinking correlated feature weights (like Ridge), making it suitable for cases with correlated variables.
Handling Multicollinearity
- Lasso can struggle with multicollinearity, as it may randomly choose one variable from a group of correlated features, ignoring the rest. This may cause instability if we want to retain multiple related features.
- Ridge is better at handling multicollinearity since it distributes weight across correlated features, making it more stable in cases where features are interrelated.
- Elastic Net is beneficial when multicollinearity is present and feature selection is desired, as it combines the benefits of both Ridge (weight distribution across correlated features) and Lasso (feature exclusion).
Coefficient Shrinking
- Lasso shrinks some coefficients entirely to zero, eliminating them from the model.
- Ridge shrinks all coefficients but doesn’t set any to zero, retaining all features.
- Elastic Net shrinks some coefficients to zero while also reducing others, creating a balanced approach between Lasso’s sparsity and Ridge’s shrinkage.
When to Use Each
- Lasso is ideal when you expect only a few features to be truly significant and when feature selection is a priority.
- Ridge is preferred when all features likely carry some predictive power and should be included, especially when multicollinearity exists.
- Elastic Net is useful when there are both correlated features and the need for feature selection. It’s particularly suitable when you want to blend Ridge’s multicollinearity handling with Lasso’s feature selection capability.
Conclusion
In summary, regularization is a powerful tool to build more robust, interpretable models by balancing complexity and generalizability. Lasso, Ridge, and Elastic Net each offer unique strengths, from feature selection to handling multicollinearity, making them invaluable in real-world applications across diverse domains like healthcare, finance, and marketing. By carefully selecting the right regularization method and tuning parameters, we can create models that not only perform well but also yield meaningful insights from data.